结合遥感与社会感知的城市区域功能识别
📑 原始论文:Deep learning-based remote and social sensing data fusion for urban region function recognition
起源:第五届百度-西安交大大数据竞赛 暨 IKCEST 首届“一带一路”国际大数据竞赛
数据集:城市区域功能分类(基于遥感影像和用户行为) - 飞桨AI Studio星河社区
摘要
基于深度学习的遥感与社会感知数据融合在城市区域功能识别的应用
城市区域区功能性识别是城市合理规划与管理的关键。
由于功能用地具有复杂的社会经济属性,仅利用遥感影像识别高密度城市的城市区域功能较为困难。社会感知的加入则具有提高识别性能的潜力。然而,如何有效地集成多源、多模态的遥感和社会感知数据,这在技术上仍然具有挑战性。
在本文中,我们提出了一种新的端到端的基于深度学习的遥感和社会数据的融合模型,用于解决这个问题。
该方法基于两种神经网络:
- 一维卷积神经网络 (CNN)
- 长短期记忆网络 (LSTM)
用来自动提取具有判别性的时间依赖的社会感知特征,并将其与通过残差神经网络提取的遥感图像特征进行融合。
利用社会数据和遥感数据的主要困难之一是两个数据源是异步的。我们开发了一种基于深度学习的策略,通过 跨模态特征一致性(CMFC) 和跨模态三元组(CMT) 的约束来解决模态缺失问题。
我们通过同时优化三种损失:分类损失、CMFC损失和CMT损失,以端到端的方式训练模型。在公开数据集上进行了广泛的实验,以证明所提出的方法在融合遥感和社会感知数据进行城市区域功能识别方面具有的有效性。结果表明,看似不相关的物理意义上的影像数据和社会活动意义上的信号确实可以相互补充,有助于增强城市区域功能识别的准确性。
问题发现
特征不足问题
传统的土地利用与覆盖(Land Use and Land Cover, LULC)分类问题与本文所研究的城市区域功能识别问题既相区别又相互联系。
LULC的识别可以仅利用物理意义上的地球表面的遥感图像信息,因为这些图片就已经能很好地捕捉地表的自然面貌,但对于功能性识别(特别是十分密集的大城市)来说,这类数据尚显不足。
有以下几点原因:
- 城市区域功能具有社会经济属性,并由相关的人类活动所决定;
- 高密度城市中的大量高层建筑(在阳光下产生)的阴影给遥感图像的处理带来了极大的挑战;
- 在东亚城市中,混合的城市功能往往聚集在一个建筑或街区中。
另一方面,如果只用社会感知数据/相关区域的人类动态行为时间序列,也不能很好地进行识别。
模态异质性与缺失
遥感和社会感知数据在来源和模态方面存在显著差异。一般情况下,遥感影像覆盖研究区域,社会感知数据则是基于位置的,因此用点、折线或多边形表示。此外,社会感知数据的特征可能是基于时间的,而不是基于空间的。
因此要实现两种多源、多模态数据的融合并不简单。关键是缓解它们之间的模态鸿沟和异质性。现有研究中解决此类问题的方法都是采用手工特征提取的方法,这需要依赖于人工劳动力和经验。
此外,另一个值得注意的问题是模型对缺失数据的鲁棒性,因为一种数据的缺失可能会严重损坏用完整数据训练的既定模型。例如,模型可以用 和 进行训练,但在某些特定区域可以用 或 进行测试(可以缺失一种)。因此,在真实世界场景中也需要针对缺失模态的有效方法。
方法介绍
形式化
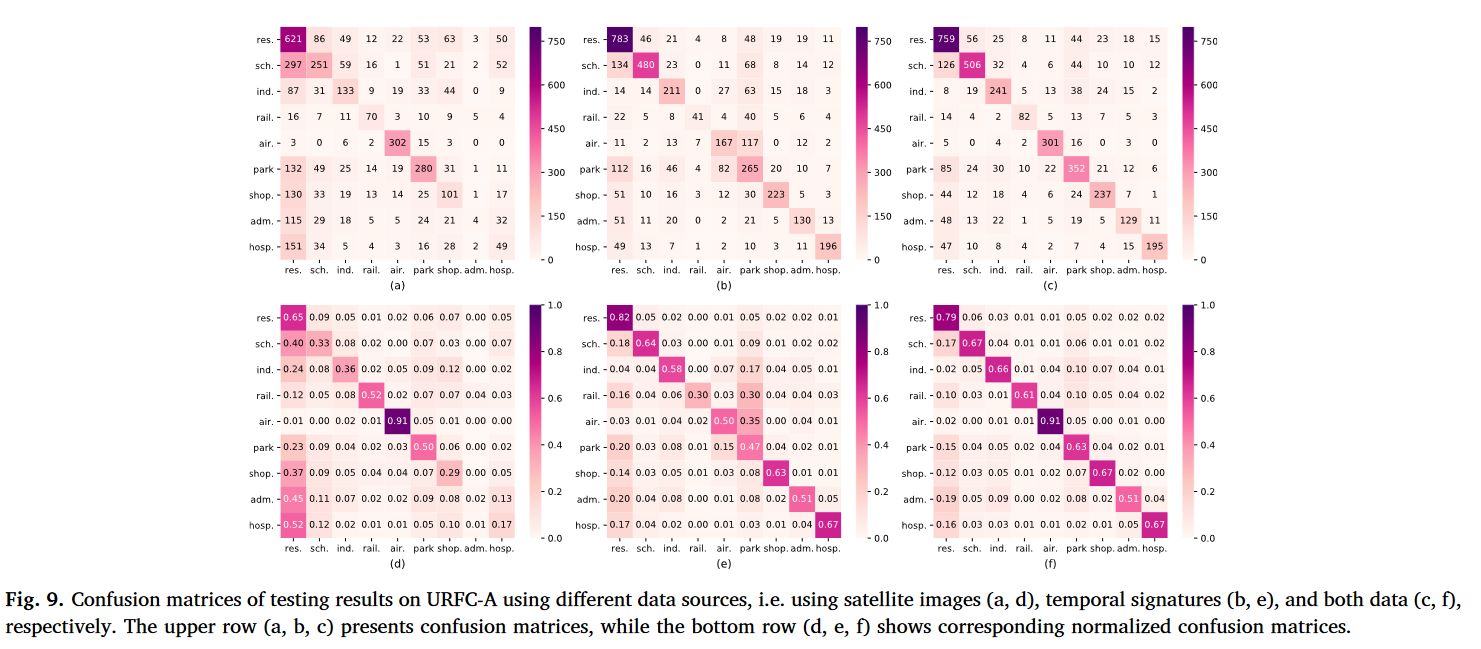
对于一个区域(Region),给定该区域的卫星遥感图像 、社会感知信号 以及该区域所属的类别 ,我们的目标是根据遥感和社会感知数据对区域类别进行预测,即通过某种方法计算得到该区域属于类别 的概率,将概率最高的类别 视为预测结果:
其中,社会感知信号是一个时间序列数据(TS),反映了人类随着时间而变化的动态情况,比如每小时拨打电话的数量、交通乘客数量等。
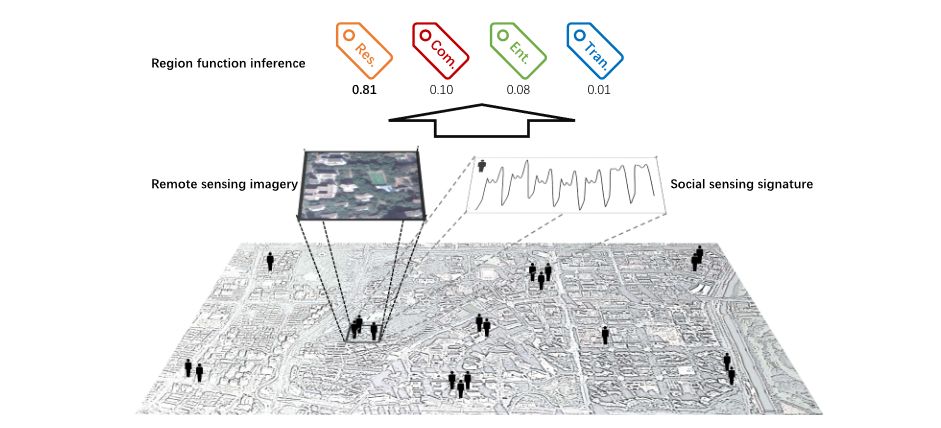
模型框架
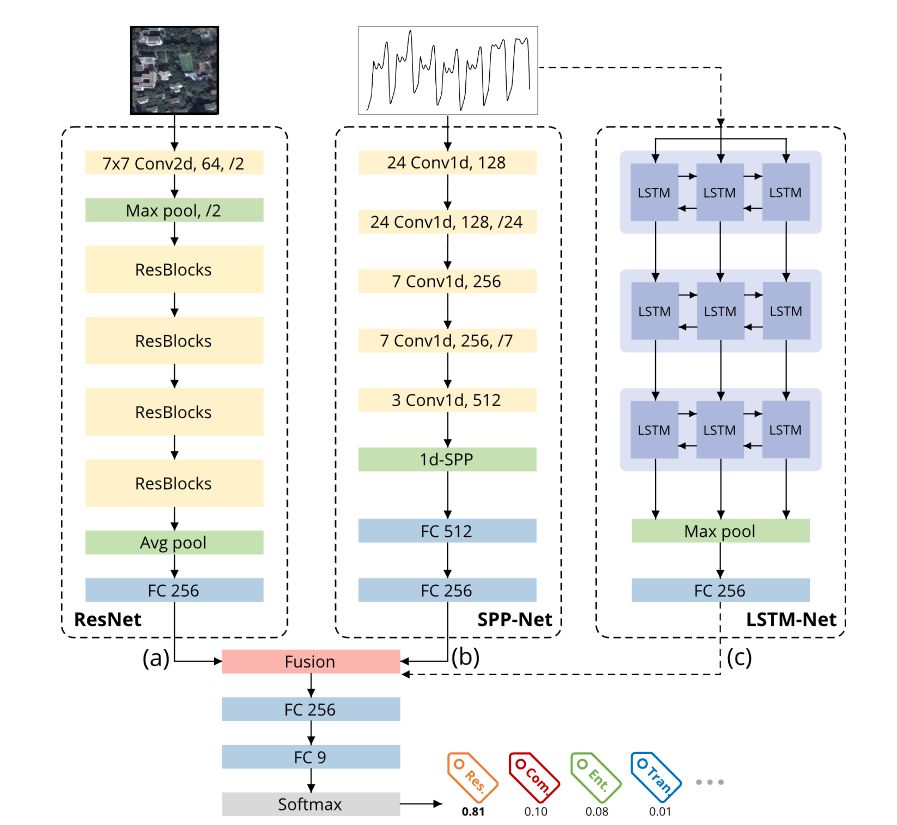
图像编码
对于数据集中分辨率为 的卫星遥感图像,本文使用经过修改的残差网络 (主要是 ResNet-18 和 ResNet-50)进行处理。训练时,初始化权重为 训练得到的权重。具体如图中(a)部分所示。
1d-SPPNet
对于数据集中的时间序列数据(每小时用户在该区域的访问量),为了很好地捕捉其时间依赖的特征,研究者考虑到 CNN 在二维图像的识别中具有卓越的性能,所以研究者希望将这种卓越的性能带到一维的数据上来。于是,图(b)部分的设计基本参考自图像识别的流程。
首先研究者设计了5层一维的卷积层(此前还包含有BN和ReLU)来提取特征,然后再模仿图像识别领域中,用来 输出固定大小的特征向量 的方法,便于后续全连接层处理。这个方法就是空间金字塔池化方法(Spatial Pyramid Pooling,SPP),研究者设计了针对时间序列数据的一维SPP,即 。
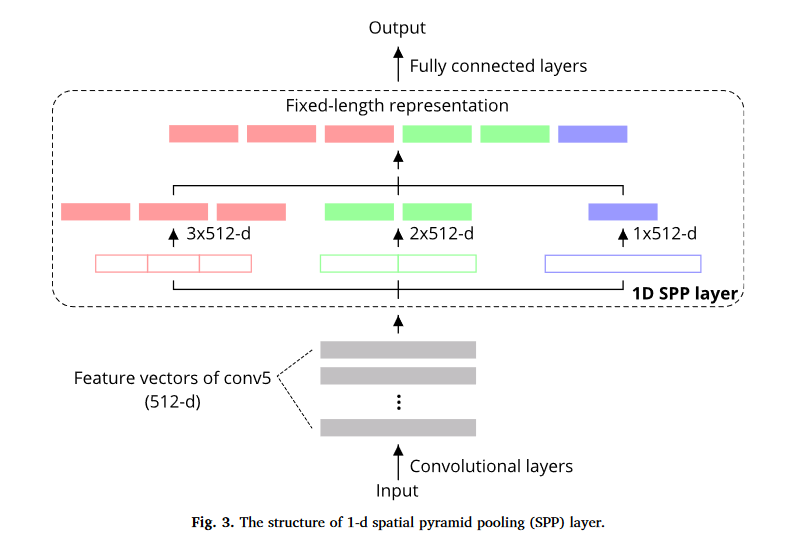
本文中,第五层卷积 Conv5 的 kernel 数 ,然后 SPP 分了三级的bin,分别取了 ,SPP 将每一个 bin 都与 Conv5 之后的 512 个向量进行 max pooling,最终就能分别得到 3 个向量,再将其拼接起来,就能得到 大小的特征向量。
关于 SPP 详见本站文章:……
双向LSTM堆叠
研究者还在时间序列数据的处理上给出了另一套方案,将 LSTM 这种可以很好处理时间序列的模型进行双向堆叠,如下图所示。
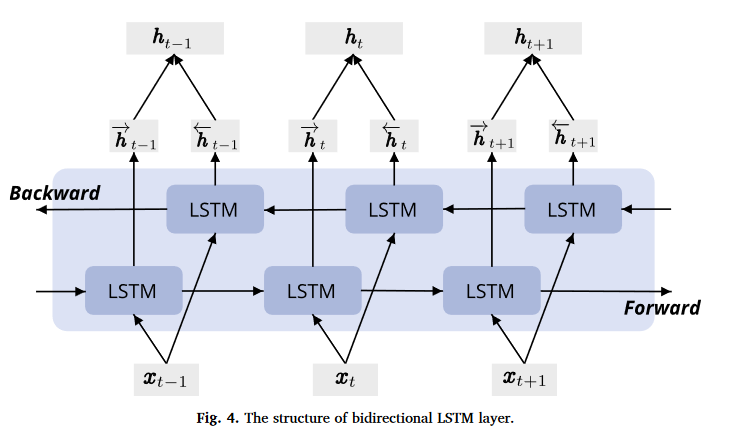
双向LSTM扩展了基本的LSTM,使模型能够从两端处理序列,它从前向和后向两个方向保存信息。此外,将双向LSTM层叠加可以增加更高级的特征提取,增强了模型学习更复杂的模式的能力。
Fusion方法
在特征的融合上,研究者给出了三种方法:
损失函数
本问题属于分类问题,所以损失函数方面采用了交叉熵。此外,研究者还加了两类损失函数,用于缓解模态异质性以及模态缺失的鲁棒性。
CMFC
跨模态特征一致性(the cross-modal feature consistency,CMFC)的损失使多模态特征在向量方向上保持一致和相似。
研究者对其利用余弦距离/余弦相似性 进行度量,并设计损失函数:
- 可见,损失函数越小,相似度越大
CMT
跨模态三元组(the cross-modal triplet,CMT)的损失进一步利用类别信息,试图提取同一类别的跨模态特征近似度。
研究者定义其损失函数为:
其中, 表示 属于同一类,但 属于另一个类别,而 表示两种模态。所以, 的意思就是属于 这个类别的特征,这个特征是由模态 给出的。
所以,这个式子的意思就是:同一类别的特征之间的距离与不同类别的特征之间的距离之差。可见,最小化这个损失函数可以使得不同模态的特征直接的相似性变高。
表示在相似对和不相似对之间施加距离的边距
思考
创新性思维
本文作者创新性地模仿二维图像的识别技术,用于时间序列这种一维数据上来。
这增加了我们在时间序列数据处理上是手段,同时也鼓励我们在看待问题时从不同角度思考,也许对已有技术进行改造,应用在一种新的数据结构里有奇效。
多模态的鲁棒性优化
多模态的特征存在的问题应该是我们在以后的研究中应该注意的。或许可以利用本文所设计的损失函数约束 CMFC 和 CMT。
特征级融合与决策级融合
文章还指出,在处理多模态的融合时,有两种策略:
- 进行特征提取,然后对特征向量在特征层面上进行融合,最后再进行预测/分类
- 单独学习两种模态的分类器,最后在决策层面上对二者的预测结果进行加权平均
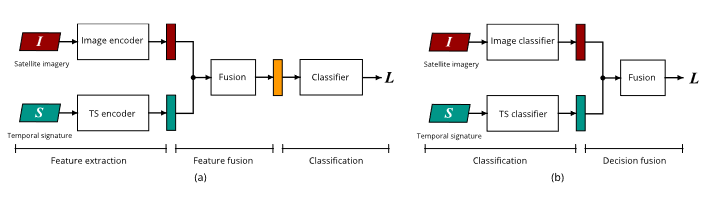
实验得出,往往前者的思路更加科学合理,得到的结果也更加精确。