Gstp2Vec - 基于图表示方法的出行活动识别
📑 原始论文:Graph-based representation for identifying individual travel activities with spatiotemporal trajectories and POI data
🌊 项目地址:XinyiHolly/Gstp2Vec
摘要
利用时空轨迹和 POI 数据的基于图表示方法的个人出行活动识别
为了了解人们频繁出行的目的,我们常常通过不同的机器学习模型(比如:贝叶斯网路、随机森林等)来识别个人的日常出行活动(比如工作、吃饭等)。
然而,这种识别/分类方法往往需要大量的劳动来进行有效的特征提取。此外,这类特征和模型的调整都主要依赖于规律性的日常出行路线和模式,因此对于较不规律的新轨迹,其适用性较差。同时,现有的大多数模型不能提取特征来明确表示有规律的出行活动序列。
因此,本文提出了一种利用时空轨迹和 POI 数据的基于图表示方法的个人出行活动识别方法,定义为 Gstp2Vec。
具体来说,对个体每日出行轨迹进行聚类,由此聚类得到的规律性的活动区域视为一个个节点,将节点连接起来以构建一个加权有向图,图的边表示两两区域之间的行程。
- 首先,每个活动区域的轨迹统计(例如:访问频率,活动持续时间等)和 POI 的分布(例如,该区域中餐馆的占比)都被编码为节点的特征。
- 其次,将出行频率、平均出行持续时间和平均出行距离编码为边的权重。
- 然后,训练一系列前馈神经网络,通过对活动节点的邻点特征进行采样和聚合(利用 K-hop 信息传递),生成活动节点的低维嵌入。将调查并收集的得到的出行活动类型标签作为反向传播的真实标签。
对实际 GPS 轨迹的实验结果表明,Gstp2Vec 通过从原始轨迹中自动学习特征嵌入,极大地减少了特征工程的工作量。该方法不仅提高了模型的泛化能力,在测试具有不同旅行模式的个体轨迹时获得了较高的辨识精度,而且具有较好的效率和鲁棒性。特别值得一提的是,我们对不同旅行模式的人最常见的日常旅行活动的识别优于目前最先进的分类模型。
问题发现
- 现有方法依赖手工特征,需要为不同的活动类型单独设计
- 现有方法泛化能力较差,对新的输入轨迹很难得到较好的精度
- 缺乏对出行活动序列(如:居住→工作→居住)进行编码的能力,这对于区分不同出行情景下不同出行模式的人的活动类型至关重要
- GCN 这种基于图的方法并没有完全利用到地理上下文等信息,且具有异质性,所以分类效果也不够好
- GraphSAGE 这种结合注意力机制的图表示学习方法可以很好地结合上下文信息,但缺乏在人类出行活动上的探索
方法介绍

本文提到的 Gstp2Vec 的总体结构如图所示。
研究者先是通过收集不同个体(用户)的足迹(footprint)数据记录(地理位置、时间戳)得到总体的出行轨迹图。然后利用 由 Liu et al. 提出的 DBSCAN 聚类方法,将每个个体的数据记录进行聚类,形成一个个活动空间(activity zone)。
Liu, X., Huang, Q. & Gao, S. Exploring the uncertainty of activity zone detection using digital footprints with multi-scaled dbscan. Int. J. Geogr. Inf. Sci. 33, 1196–1223 (2019).
然后将这些活动空间视为一个节点,构建一个有向图(暗含用户的运动轨迹)。
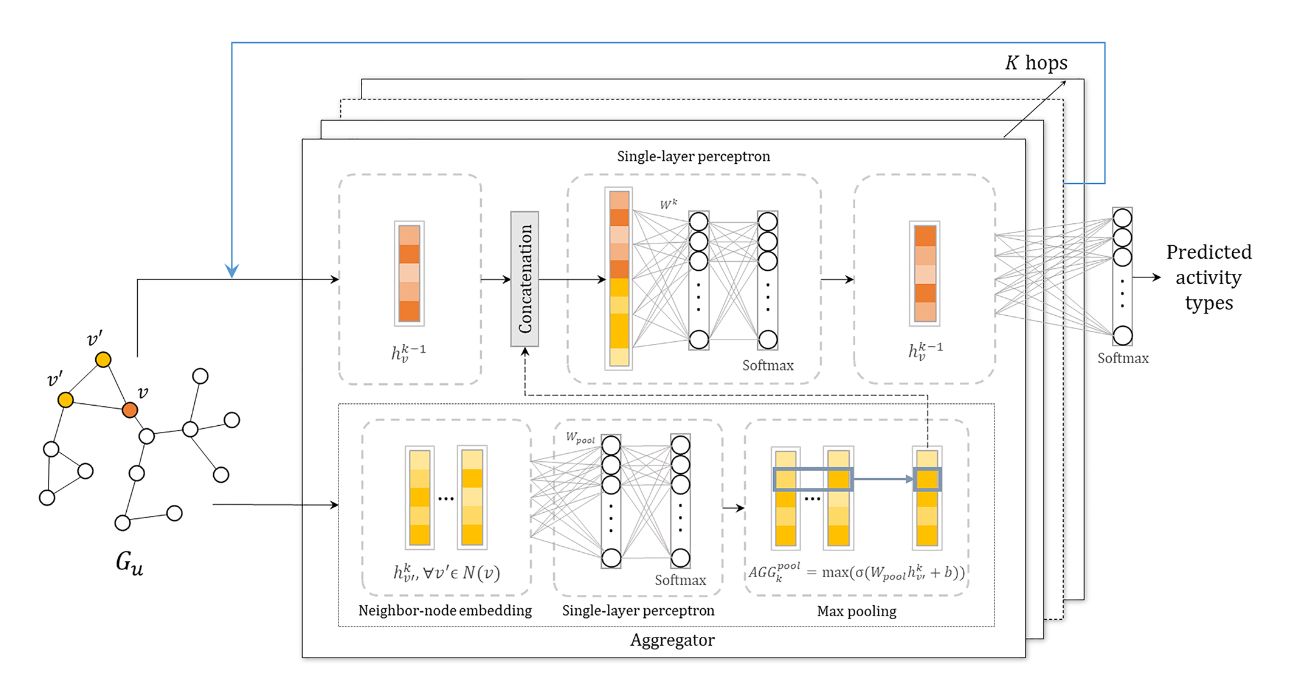
分别对节点和边进行特征选择,利用 MPNN 的 K-hop 策略进行信息传递(实现空间上下文信息的携带)。该 embedding 过程可由设计的聚合器(aggregator)实现。
最后,通过 层对表示特征的多分类,利用交叉熵作为损失函数进行训练。
节点特征
某一节点 的特征记作 ,由三个方面的属性特征组成:
边权重
任意两个节点的边 的权重(实际上也是特征) 也由三个属性特征组成:
聚合器与训练
节点特征的嵌入/聚合的整个流程如下图所示。
读后感
u1s1,这篇文章发表在 Scientific Reports 倒也正常。是目前来说虽然读得不慢但是却读得比较难受的一篇文章。
整个模型框架比较简单,但前半部分废话较多,用到的词汇也不太规范。反而,在相较容易的特征选择方面花了较大的笔墨刻画。工作量貌似并不多。而 BDSCAN 聚类方法却没有做出解释就拿来使用了,以及 也没有做简要解释,公式也没有解释清楚,需要读者自己参透。